STREAM-memory-benchmark-tools.md
- @name 没错, 是时候进行内存性能测试了
- @author karminski <code.karminski@outlook.com>
- @version 20240925:1
我们通常跑分很关注CPU分数, 显卡帧数, 硬盘读写速度. 但有没有想过给内存跑分?
内存性能直接影响内存密集型的应用, 例如网络文件存储, LLM, 挖矿等. 所以就有了这篇如何进行内存测试的教程.
我们要使用的是 STREAM 来自 virginia 大学开发.
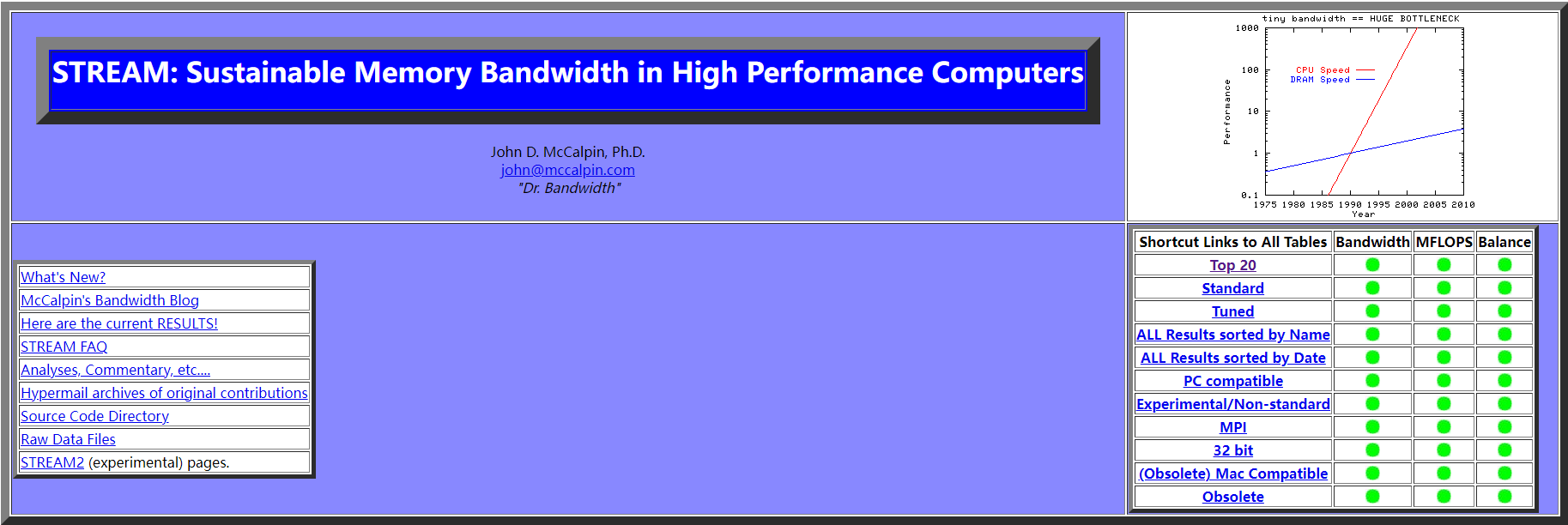
这个软件历史很久了, 我在邮件列表中甚至看到了1991年的邮件.

项目的官网地址 https://www.cs.virginia.edu/stream/
源代码 STREAM
https://github.com/jeffhammond/STREAM
默认构建使用 make stream_c.exe 即可.
这个默认包含了 fortran 测试程序, 如果想用 fortran 可以用下面的命令安装.
sudo apt-get install gfortran
默认测试结果:
root@nagisa:/data/repo/github.com/others/STREAM# ./stream_c.exe
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 10000000 (elements), Offset = 0 (elements)
Memory per array = 76.3 MiB (= 0.1 GiB).
Total memory required = 228.9 MiB (= 0.2 GiB).
Each kernel will be executed 10 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 104
Number of Threads counted = 104
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 10504 microseconds.
(= 10504 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 90333.6 0.001843 0.001771 0.001878
Scale: 68548.4 0.002452 0.002334 0.002965
Add: 77870.6 0.003122 0.003082 0.003200
Triad: 85685.5 0.002874 0.002801 0.003290
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
单核心测试结果:
root@nagisa:/data/repo/github.com/others/STREAM# OMP_NUM_THREADS=1 OMP_PROC_BIND=close ./stream_c.exe
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 10000000 (elements), Offset = 0 (elements)
Memory per array = 76.3 MiB (= 0.1 GiB).
Total memory required = 228.9 MiB (= 0.2 GiB).
Each kernel will be executed 10 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 1
Number of Threads counted = 1
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 7787 microseconds.
(= 7787 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 11103.4 0.014540 0.014410 0.014640
Scale: 13081.4 0.012254 0.012231 0.012281
Add: 14634.9 0.016435 0.016399 0.016473
Triad: 14582.5 0.016495 0.016458 0.016573
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
同样包含了 icc 版本, 构建可以使用命令 make stream.icc, 测试结果:
root@nagisa:/data/repo/github.com/others/STREAM# ./stream.omp.AVX2.80M.20x.icc
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 80000000 (elements), Offset = 0 (elements)
Memory per array = 610.4 MiB (= 0.6 GiB).
Total memory required = 1831.1 MiB (= 1.8 GiB).
Each kernel will be executed 20 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 104
Number of Threads counted = 104
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 19235 microseconds.
(= 19235 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 79879.6 0.016813 0.016024 0.017515
Scale: 80548.4 0.016962 0.015891 0.023003
Add: 90745.9 0.023681 0.021158 0.055701
Triad: 90484.9 0.021876 0.021219 0.022613
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
Intel fork memory-bandwidth-benchmarks
https://github.com/intel/memory-bandwidth-benchmarks
这个是 Intel 的优化版本, 可以使用 AVX, AVX512, AVX2 进行测试.
Makefile 默认需要 icc 下载地址 https://www.intel.com/content/www/us/en/developer/articles/news/free-intel-software-developer-tools.html
记得安装 hpckit, basekit 是不包含icc的. 然后安装了hpckit后, 恭喜你, 还是没有icc, 这时候再运行
apt install intel-oneapi-compiler-dpcpp-cpp-and-cpp-classic source /opt/intel/oneapi/setvars.sh
就有 icc 了. 至于为什么, 请去问 intel oneapi 的产品经理 (intel 貌似放弃 icc 路线, 改用 llvm 魔改后的编译器了).
AVX2 测试结果:
root@nagisa:/data/repo/github.com/others/memory-bandwidth-benchmarks# ./stream_avx2.bin ------------------------------------------------------------- STREAM version $Revision: 5.10 $ ------------------------------------------------------------- This system uses 8 bytes per array element. ------------------------------------------------------------- Array size = 269000000 (elements), Offset = 0 (elements) Memory per array = 2052.3 MiB (= 2.0 GiB). Total memory required = 6156.9 MiB (= 6.0 GiB). Each kernel will be executed 100 times. The *best* time for each kernel (excluding the first iteration) will be used to compute the reported bandwidth. ------------------------------------------------------------- Number of Threads requested = 104 Number of Threads counted = 104 ------------------------------------------------------------- Your clock granularity/precision appears to be 1 microseconds. Each test below will take on the order of 60641 microseconds. (= 60641 clock ticks) Increase the size of the arrays if this shows that you are not getting at least 20 clock ticks per test. ------------------------------------------------------------- WARNING -- The above is only a rough guideline. For best results, please be sure you know the precision of your system timer. ------------------------------------------------------------- Function Best Rate MB/s Avg time Min time Max time Copy: 121733.1 0.053849 0.035356 0.176289 Scale: 120814.1 0.047681 0.035625 0.167932 Add: 132173.1 0.069584 0.048845 0.187420 Triad: 132300.9 0.071247 0.048798 0.181760 ------------------------------------------------------------- Solution Validates: avg error less than 1.000000e-13 on all three arrays -------------------------------------------------------------
AVX512 测试结果:
root@nagisa:/data/repo/github.com/others/memory-bandwidth-benchmarks# ./stream_avx512.bin
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 269000000 (elements), Offset = 0 (elements)
Memory per array = 2052.3 MiB (= 2.0 GiB).
Total memory required = 6156.9 MiB (= 6.0 GiB).
Each kernel will be executed 100 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 104
Number of Threads counted = 104
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 40596 microseconds.
(= 40596 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 126547.7 0.038291 0.034011 0.085720
Scale: 136034.2 0.037027 0.031639 0.084702
Add: 139622.7 0.051695 0.046239 0.087387
Triad: 136756.3 0.052373 0.047208 0.088289
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
AVX 测试结果:
root@nagisa:/data/repo/github.com/others/memory-bandwidth-benchmarks# ./stream_avx.bin
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 269000000 (elements), Offset = 0 (elements)
Memory per array = 2052.3 MiB (= 2.0 GiB).
Total memory required = 6156.9 MiB (= 6.0 GiB).
Each kernel will be executed 100 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 104
Number of Threads counted = 104
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 39190 microseconds.
(= 39190 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 115364.1 0.038399 0.037308 0.057047
Scale: 122412.4 0.039427 0.035160 0.088110
Add: 130445.6 0.052188 0.049492 0.088966
Triad: 128387.9 0.052589 0.050285 0.097945
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
AMD version
AMD 的优化版本同样也有, 地址在这里 https://www.amd.com/en/developer/zen-software-studio/applications/spack/stream-benchmark.html
MAC version
MAC 需要使用 GCC 或 LLVM 编译, 详见 https://github.com/jeffhammond/STREAM/issues/14.
直接 brew install gcc 即可, 然后把 Makefile 里面的 gcc 修改成 brew 安装的 gcc (通常在 /opt/homebrew/bin 里面).
下面是 MAC M2 Ultra 128GB 的单核心测试结果:
(base) karminski@kurumi STREAM % OMP_NUM_THREADS=1 OMP_PROC_BIND=close ./stream_c.exe
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 10000000 (elements), Offset = 0 (elements)
Memory per array = 76.3 MiB (= 0.1 GiB).
Total memory required = 228.9 MiB (= 0.2 GiB).
Each kernel will be executed 10 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 1
Number of Threads counted = 1
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 6237 microseconds.
(= 6237 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 100117.7 0.001660 0.001598 0.001673
Scale: 55343.0 0.002929 0.002891 0.003199
Add: 76381.6 0.003172 0.003142 0.003355
Triad: 76824.6 0.003164 0.003124 0.003292
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
下面是 MAC M2 Ultra 128GB 的24核心测试结果:
(base) karminski@kurumi STREAM % ./stream_c.exe
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 10000000 (elements), Offset = 0 (elements)
Memory per array = 76.3 MiB (= 0.1 GiB).
Total memory required = 228.9 MiB (= 0.2 GiB).
Each kernel will be executed 10 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 24
Number of Threads counted = 24
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 718 microseconds.
(= 718 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 255555.5 0.000673 0.000626 0.000699
Scale: 236632.1 0.000728 0.000676 0.000782
Add: 263723.6 0.000967 0.000910 0.001023
Triad: 260044.7 0.000964 0.000923 0.000994
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
结论
我的机器是个 DELL T7950, 双路 Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz, 内存插了8条 Samsung 32GiB DDR4 2666 .
从数据来看, Intel优化版本的 AVX512 数据表现最好, Copy 速度单核心的话是 11103.4 MB/s. 104 个核心达到了 126547.7 MB/s.
我的另一个 MAC M2 Ultra 128GB 单核心是 100117.7 MB/s, 24核心是 255555.5 MB/s.
作为对比, 最近看到了 STH 上面放出了 Intel Xeon 6980P 的数据, 使用了 Micron 64GB DDR5 MRDIMM 8800, 其中单核 达到了26489.7 MB/s, 128核心达到了 535265.1 MB/s.
STH 还引用了 NVIDIA Grace GH200 480GB (标称统一内存带宽 900 GB/s) 的数据, 72 核心的数据是 333626.0 MB/s.
比较有意思的是, STREAM 还搞了个 top 20 的数据, 榜一是 3072 CPU 的 SGI_UV_3000 超算, copy 速度达到了 12799304.0 MB/s (12TB/s).
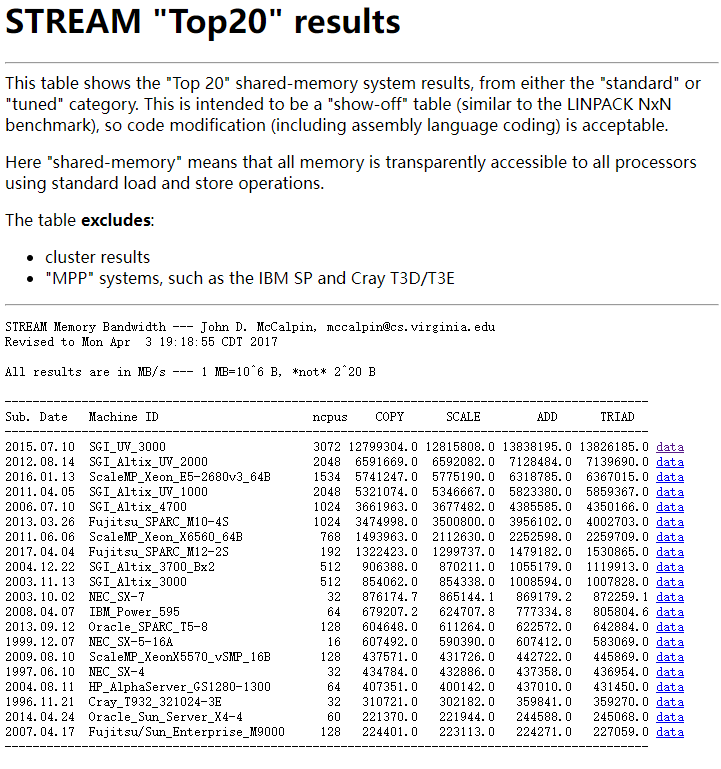
机器长这样:
