Assembly-Language-v3-Reading-Notes.md
- @name 汇编语言 第三版 读书笔记
- @author karminski <code.karminski@outlook.com>
- @version 20200114:1
第一章, 基础知识
机器语言
汇编语言的产生
汇编语言的组成
汇编语言有3类指令:
- 汇编指令, 机器码的助记符, 有对应的机器码. 决定了汇编语言的特性.
- 伪指令, 没有对应的机器码, 由编译器执行, 计算机并不直接执行.
- 其他符号, 没有对应的机器码, 由编译器识别.
存储器
存储指令和数据, 内存.
指令和数据
指令即数据.
存储单元
CPU 对存储器的读写
总线从逻辑上分为 地址总线, 控制总线, 数据总线.
地址总线
CPU位宽与地址总线并不一定对齐. 比如 8086.
寻址不会拆分, 因此地址总线宽度直接决定了可用内存容量, 当然也有 RDIMM, LPRDIMM 这样的技术.
这二者中间涉及了 逻辑地址 到物理地址的转换.
数据总线
8088 CPU 数据总线宽度为 8, 8086 为 16, 长的数据会拆分.
控制总线
宽度决定控制能力.
这里指出了每个指令均由专用线路来控制.
习题
- 地址总线宽度为16, 8KB x 8 x 1024 = 65536 bit = 2^16 即 总线宽度 16.
- 1KB存储器有 1024 个存储单元, 编号 0 - 1023
- 1KB 可以存储 8192 bit, 1024 Byte.
-
- 8KB, 2^y / 8 / 1024
- 8, 8, 16, 16, 32
- 64, 32
- 二进制
内存地址空间 (概述)
即可访问的地址单元构成的空间
主板
接口卡
Adapter 啦, 名如其功能.
各类存储器芯片
从读写属性上分为:
- 随机存储器 RAM random access memory
- 只读存储器 ROM read only memeory
内存地址空间
CPU 将系统中各类存储器看作一个逻辑存储器, 即内存地址空间.
第二章, 寄存器
一个典型的 CPU 由 运算器, 控制器, 寄存器 等器件组成, 这些由 CPU 内部总线链接.
通用寄存器
AX, BX, CX, DX 为16位通用寄存器.
为了向上兼容8位, AX寄存器可分为 AH 和 AL.
字在寄存器中的存储
字, word, 一个 word 由 两个字节组成.
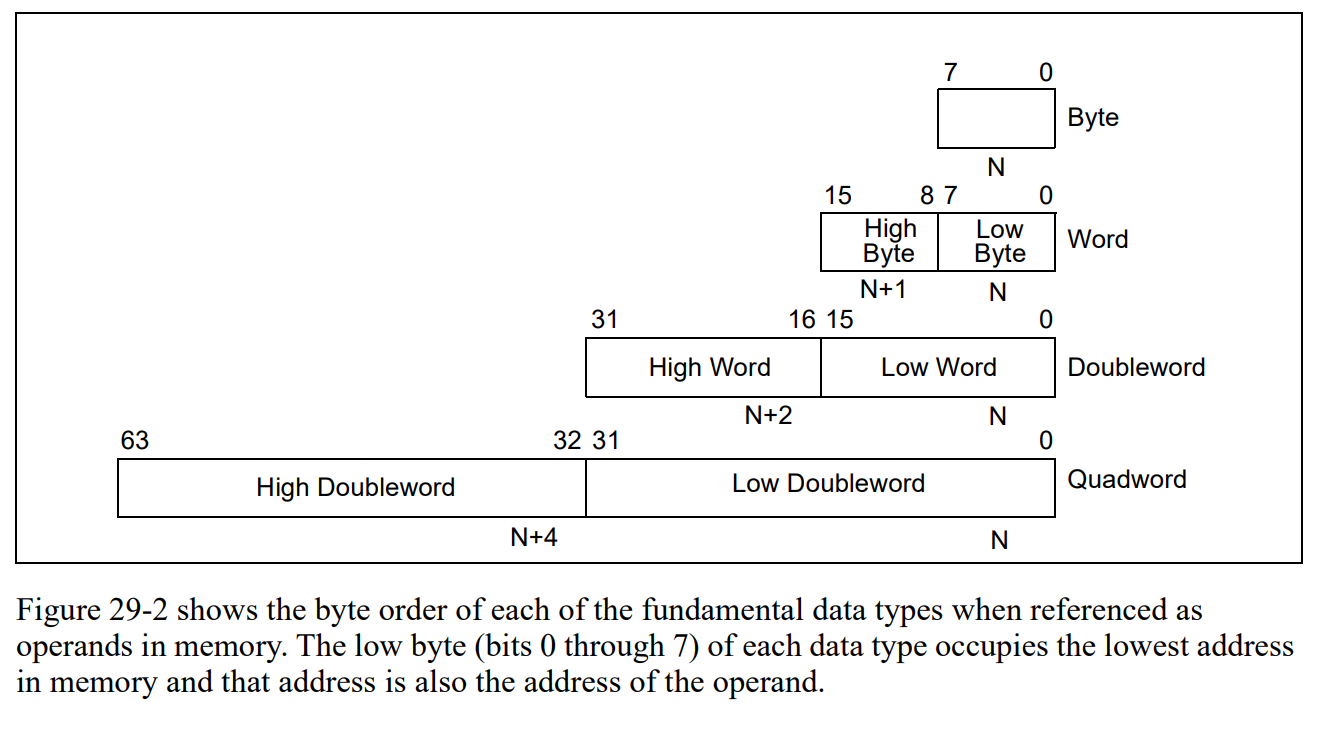
A byte is eight bits, a word is 2 bytes (16 bits), a doubleword is 4 bytes (32 bits), and a quadword is 8 bytes (64 bits).
Ref:
Intel Data Types and Addressing Modes
几条汇编指令
介绍了 MOV, ADD
物理地址
16 位结构的 CPU
8086 是 16 位机器.
8086 CPU 给出物理地址方法
8086 有 20 位地址总线. 但其为16位架构, 故使用两个16位地址合成一个20位地址. 其内部有个地址加法器用于合成.
两个16位地址一个称为段地址, 一个称为偏移地址. 段地址 x 16 + 偏移地址. 即左移4位
0000 0000 0000 0000
0000 0001 0010 0011 // 0123
0001 0010 0011 0000 // 1230
0000 0000 1100 1000 // 00C8
1 0010 0011 1100 1000 // 123C8
段地址是向高位对齐的.
段地址 x 16 + 偏移地址=物理地址 的本质含义
段的概念
CPU可以用不同的段地址和偏移地址形成同一个物理地址.
段寄存器
8086 有 CS, DS, SS, ES 四个段寄存器.
CS 和 IP
CS 为代码段寄存器, IP 为指令指针寄存器.
修改 CS, IP 的指令
JMP 2AE3:3 CPU 从 CS=2AE3, IP=0003 处读取指令.
也可以只控制 IP:
JMP AX,
before: AX=1000, CS=2000, IP=0003
after: AX=1000, CS=2000, IP=1000 <-这里要注意
-
问题 2.3
CS=2000, IP=0000, AX=0000, BX=0000, CX=0000
MOV AX, 6622
CS=2000, IP=0003, AX=6622, BX=0000, CX=0000
JMP 1000:3
CS=1000, IP=0003, AX=6622, BX=0000, CX=0000
MOV AX, 0000
CS=1000, IP=0006, AX=0000, BX=0000, CX=0000
MOV BX, AX
CS=1000, IP=0008, AX=0000, BX=0000, CX=0000
JMP BX
CS=1000, IP=000A, AX=0000, BX=0000, CX=0000
MOV AX, 0123
CS=1000, IP=0000, AX=0123, BX=0000, CX=0000
即 IP 自动指向执行完毕后的偏移位置, 因为 CPU 自动运行 CS:IP 指向的数据, 而且是顺序执行的.
代码段
存放代码. 其得到执行需要定义 CS 及 IP.
8086 有 四个段寄存器, 其中 CS 用来存放指令的段地址. IP 存放指令的偏移地址.
8086 中, 任意时刻, CPU 将 CS:IP 指向的内容当作指令执行.
其工作过程:
- 从 CS:IP 之乡的内存单元读取指令, 读取的指令进入指令缓冲器.
- IP 指向下一条指令.
- 执行指令, 重复这一过程.
实验 1
debug 命令, 使用文档见: DOS-Debug
-r 打印寄存器状态/修改寄存器状态
-d {segment address}:{ address} dump, 查看指定内存地址中的内容
-e {segment address}:{ address} 修改指定内存地址中的内容
-u 打印本机的CPU机器码
-t 运行当前cs:ip指向的命令
-a 直接使用汇编编写命令
Chapter 3, 寄存器(内存访问)
3.1 内存中字的存储
字单元, 即 16bit, 存储一个字.
3.2 DS 和 [address]
[...] 表示内存单元, [...]中的0表示内存单元的偏移地址, DS 段寄存器中的数据为段地址. 这里需要先将段地址送入通用寄存器, 然后再传递给DS.
3.3 字的传送
问题 3.3 注意字的大小, 是图中的两个单元.
3.4 mov, add, sub 指令
3.5 数据段
可以将小于64KB的连续内存地址定义为段.
3.6 栈
3.7 CPU提供的栈机制
用内存当栈, 以字为单位进行操作. CPU 提供PUSH和POP指令. CS, IP 寄存器负责指向栈的基地址, 段寄存器SS存放栈顶地址, 寄存器SP存放偏移地址. 即, SS, SP 指向栈顶元素. PUSH 和 POP 指令执行时, CPU从SS和IP中的得到栈顶地址.
入栈时, 数据从高地址向低地址增长.
3.8 栈顶越界的问题
即 POP 和 PUSH 都可能越界, 需要手动控制.
3.9 PUSH, POP 指令
PUSH, POP 指令可以操作寄存器和内存单元.
- 问题 3.7
即简单的入栈过程:
MOV AX, 1000H
MOV SS, AX
MOV SP, 0010H
PUSH AX
PUSH BX
PUSH DS
设置SS, SP寄存器指定当前栈顶地址, 然后PUSH即可. SS 寄存器不能直接设置立即数, 所以要用AX寄存器.
- 问题 3.8
强调了入栈与出栈顺序相反, 另外寄存器清零可以用 SUB AX, AX, 或 MOV AX, 0.
- 问题 3.9
即利用栈的特性交换数据.
- 问题 3.10
MOV AX, 1000H
MOV SS, AX
MOV SP, 0002H
MOV AX, 2266H
PUSH AX
栈段
即指定固定长度的空间当栈空间使用.
-
问题 3.11
-
问题 3.12
-
段的综述
即表述的是, 在内存中, 数据与代码并无区别, 段也是人为划分的. 但CPU为了让程序符合架构模型, 故存在段的概念, 并提供了操作段的寄存器:
-
数据段, 地址存放在DS
-
代码段, CS
-
栈段, SS
-
检测点 3.2
MOV AX, 1000H
MOV DS, AX
实验2 用机器指令和汇编指令
即, D命令本身也依靠段寄存器的地址来显示内容. 同样, E, A, U 命令也可以.
由于中断的原因, T 命令并不能完全单步. 修改SS寄存器时, 吓一条指令也会被执行.
Chapter 4, 第一个程序
4.1 一个源程序从写出到执行的过程
讲了编译, 链接, 执行的过程
4.2 源程序
assume cs:codesg
codesg segment
mov ax, 0123h
mov bx, 0456h
add ax, bx
add ax, ax
mov ax, 4c00h
int 21h
codesg ends
end
- 伪指令
{} segment ... {} ends 伪指令, 用来定义一个段.
end 伪指令, 标记程序结束.
assume 伪指令, 定义段寄存器与段代码的关联.
- 程序返回
mov ax 4c00H
int 21H
4.3 编辑源程序
4.4 编译
masm 1.exe
4.5 连接
link 1.exe
4.6 以简化的方式进行编译和连接
4.7 1.exe 的执行
4.8 谁将可执行文件中的程序装载进入内存并使他运行
- 问题 4.2
command.com 是DOS系统的shell, 如果执行其他程序, command 根据文件名找到可执行文件, 然后将可执行文件载入内存, 设置 CS:IP 指向程序入口, 然后运行程序.
- 汇编程序从写出到执行的过程
编程->1.asm->编译->1.obj->连接->1.exe->加载->内存中的程序->运行
(edit) (masm) (link) (command) (CPU)
4.9 程序执行过程的跟踪
SA:0 空闲内存
SA:0 PSP 区(用于DOS系统与被加载程序通信)
SA+10H:0 程序区
实验3, 编程, 编译, 连接, 跟踪
assume cs:codesg
codesg segment
MOV AX, 2000H
MOV SS, AX
mov sp, 0
add sp, 10
pop ax
pop bx
push ax
push bx
pop ax
pop bx
mov ax, 4c00h
int 21h
codesg ends
end
ax 2000H
ss 2000H
SS 2000H, SP 0
SS 2000H, SP 0A
AX 0000, BX 0000
AX 0000, BX 0000
AX 0000, BX 0000
049A:0040 CD20 INT 20
049A:0042 FF9F00EA CALL FAR [BX+EA00]
049A:0046 FFFF ??? DI
049A:0048 AD LODSW
049A:0049 DE4202 FIADD WORD PTR [BP+SI+02]
049A:004C 92 XCHG DX, AX
049A:004D 017002 ADD [BX+SI+02], SI
...
Chapter 5, [BX] 和 loop 指令
- [BX] 和内存单元的描述
即用BX作为偏移地址. MOV 时会自动判断是word还是byte.
-
loop
-
我们定义的描述性的符号"()"
(ax)=((ds)*16+2) 等同于 mov ax,[2]
(sp)=(sp)-2
((ss)*16+(sp))=(ax) 等同于 push ax
- 约定符号 idata 表示常量
mov ax,[idata] 代表 mov ax,[1] 等.
5.1 [BX]
- 问题 5.1
DS 2000H
AX 00BE
BX 1002
5.2 Loop 指令
assume cs:code
code segment
mov ax, 2
mov cx, 11
s: add ax, ax
loop s
mov ax, 4c00h
int 21h
code ends
end
即 loop 使用 cx 作为计数器.
- 问题 5.2
assume cs:codesg
codesg segment
mov ax, 123
mov cx, 236
p1: add ax, 123
loop s
mov ax, 4c00h
int 21h
codesg ends
end
- 问题 5.3
有点无厘头...
5.3 在 Debug 中跟踪用 loop 指令实现的循环程序
assume cs:code
code segment
mov ax, 0ffffh ; 因为是数据, 前缀必须加0
mov ds, ax
mov bx, 6
mov al, [bx] ; 这里应该是把ROM的内容搞进去了, 我看这部分内存貌似是BIOS时间? 我的DOSBOX值是31, 不是32
mov ah, 0
mov dx, 0
mov cx, 3
s:add dx, ax
loop s
mov ax, 4c00h
int 21h
code ends
end
介绍了 debug 的 g命令, 可以让IP寄存器到达指定位置停止.
p 命令, 运行结束循环. 用 g也可以代替. 很奇怪我的debug不支持p命令.
5.4 debug 和汇编编译器masm对指令的不同处理
这里指出了 debug 与 asm 程序在立即数上的不同处理.
如果直接写[idata] 会被当成立即数而不是内存偏移地址. 所以要么送入 BX 并设置 DS 然后写成 MOV AL, [BX], 要么就写成 MOV AL, DS:[0].
即, 需要显示声明用哪个段寄存器.
5.5 loop 和 [bx] 的联合应用
assume cs:code
code segment
mov ax, 0fffh
mov ds, ax
mov dx, 0
mov al, ds:[0]
mov ah, 0
add ax, ax
mov al, ds:[1]
mov ah, 0
add dx, ax
mov al, ds:[2]
...
这里al, ah 分别赋值防止溢出.
- 问题 5.4
改进为用loop.
assume cs:code
code segment
mov ax, 0ffffh
mov ds, ax
mov bx, 0
mov dx, 0
mov cx, 12
s:mov al, [bx]
mov ah, 0
add dx, ax
inc bx
loop s
mov ax, 4c00h
int 21h
code ends
end
5.6 段前缀
mov ax, ds:[bx]
mov ax, cs:[bx]
mov ax, ss:[bx]
mov ax, es:[bx]
mov ax, ss:[0]
mov ax, cs:[0]
这些均合法, ds, cs, ss, es 这些出现在访问内存单元指令中, 用于显式指明内存单元的段地址, 被称为段前缀.
5.7 一段安全的空间
讲了随意操作内存带来的问题. 0:200-0:2FF 在DOS中存有数据.
5.8 段前缀的使用
assume cs:code
code segment
mov bx, 0
mov cx, 12
s:mov ax, 0ffffh
mov ds, ax
mov dl, [bx]
mov ax, 0020h
mov ds, ax
mov [bx], dl
inc bx
loop s
mov ax, 4c00h
int 21h
code ends
end
优化, 使用两个寄存器
assume cs:code
code segment
mov ax, 0ffffh
mov ds, ax
mov ax, 0020h
mov es, ax
mov bx, 0
mov cx, 12
s:mov dl, [bx]
mov es:[bx], dl
inc bx
loop s
mov ax, 4c00h
int 21h
code ends
end
- 实验 4, [BX] 和 loop 的使用
- 向内存 0:200-0:23F依次传送数据 0-63(3FH)
assume cs:code
code segment
mov ax, _
mov ds, ax
mov ax, 0020h ; 复制到 0:0200
mov es, ax
mov bx, 0
mov cx, _
s:mov al, [bx]
mov es:[bx], al
inc bx
loop s
mov ax, 4c00h
int 21h
code ends
end
Chapter 6, 包含多个段的程序
本章主要讨论:
- 在一个段中存放数据, 代码, 栈, 我们先来体会一下不使用多个段时的情况.
- 将数据, 代码, 栈放入不同的段中
6.1 在代码段中使用数据
assume cs:code
code segment
dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h; define word, 定义字型数据
mov bx, 0
mov ax, 0
mov cx, 8
s:add ax, cs:[bx]
add bx, 2
loop s
mov ax, 4c00h
int 21h
code ends
end
dw 定义的数据位于, cs:0 - cs:e. 即如同代码所写, 在代码段的开始.
04ae:0000 23 01 56 04 89 07 BC 0A-EF 0D ED 0F BA 0C 87 09
这种情况 debug 加载程序后, 需要手动指定 IP 寄存器位置. padding 过去 dw 的位置. 同样, 程序本身也需要修改才能运行:
assume cs:code
code segment
dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h; define word, 定义字型数据
start:mov bx, 0
mov ax, 0
mov cx, 8
s:add ax, cs:[bx]
add bx, 2
loop s
mov ax, 4c00h
int 21h
code ends
end start
6.2 在代码中使用栈
即预先分配出一段内存在代码段中当作栈用.
assume cs:codesg
codesg segment
dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
start: mov ax, cs
mov ss, ax
mov sp, 30h
mov bx, 0
mov cx, 8
s: push cs:[bx]
add bx, 2
loop s
mov bx, 0
mov cx, 8
s0: pop cs:[bx]
add bx, 2
loop s0
mov ax, 4c00h
int 21h
codesg ends
end start
- 检测点 6.1
6.3 将数据, 代码, 栈放入不同的段
assume cs:code, ds:data, ss:stack
data segment
dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h
data ends
stack segment
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax, stack
mov ss, ax
mov sp, 20h ; set ss:sp to stack:20
mov ax, data
mov ds, ax ; set ds to data segment
mov bx, 0 ; set ds:bx to data segment first element
mov cx, 8
s: push [bx]
add bx, 2
loop s
mov bx, 0
mov cx, 8
s0: pop [bx]
add bx, 2
loop s0
mov ax, 4c00h
int 21h
code ends
end start
其中, 数据段和栈段的地址可以用定义的标识符来直接获取地址. 例如 mov ax, data. 获取data段中的 0abch数据的地址即 data:6.
注意不能直接让段寄存器使用, 所以还是要这么操作:
mov ax, data
mov ds, ax
mov bx, ds:[6]
CPU 并没有具体区分段的区别, 这种区分是代码定义的.
实验 5 编写调试具有多个段的程序
assume cs:code, ds:data, ss:stack
data segment
dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax, stack
mov ss, ax
mov sp, 16
mov ax, data
mov ds, ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax. 4c00h
int 21h
code ends
end start
- 0456h, 0123h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h
Chapter 7, 更灵活的定位内存地址的方法
7.1 and 和 or 指令
and 指令, 按位与运算
or 指令, 按位或运算
7.2 关于 ASICC 码
没啥新鲜的
7.3 以字符形式给出的数据
assume cs:code, ds:data
data segment
db 'unIX'
db 'foRK'
data ends
code segment
start: mov al, 'a'
mov bl, 'b'
mov ax, 4c00h
int 21h
code ends
end start
7.4 大小写转换的问题
小写字幕-20h即可得到大写字母. 或判断第5位是否为0.
assume cs:codesg, ds:datasg
datasg segment
db 'BaSic'
db 'iNfOrMaTiOn'
datasg ends
codesg segment
start: mov ax, datasg
mov ds, ax
mov bx, 0
mov cx, 5
s:mov al[bx]
and al 11011111B
mov [bx], al
inc bx
loop s
mov bx, 5
mov cx, 11
s0:mov al,[bx]
or al, 00100000B
mov [bx], al
inc bx
loop s0
mov ax, 4c00h
int 21h
codesg edns
end start
程序利用AND, 并使用 11011111B 来进行按位与, 达到变为小写的目的.
7.5 [bx+idata]
mov ax, [bx+200] 即将 ds:bx+200 位置的数据放入ax.
7.6 用[bx+idata]的方式进行数组的处理
简化上面的大小写转换的例子:
mov ax, datasg
mov ds, ax
mov bx, 0
mov cx, 5
s:mov al, [bx]
and al,11011111b
mov [bx],al
mov al, [5+bx]
or al, 00100000b
mov [5+bx], al
inc bx
loop s
7.7 SI 和 DI
SI 和 DI 是8086中类似 BX 的寄存器. 不过不能够分成2个8位寄存器使用.
- 问题7.2
assume cs:codesg, ds:datasg
datasg segment
db 'welcode to masm!'
db '................'
data sg ends
codesg segment
start: mov ax, datasg
mov ds, ax
mov si, 0
mov di, 16
mov cx, 8
s: mov ax, [si]
mov [di], ax
add si, 2
add di, 2
loop s
mov ax, 4c00h
int 21h
codesg ends
end start
- 问题 7.3
codesg segment
start: mov ax, datasg
mov ds, ax
mov si, 0
mov cx, 8
s: mov ax, 0[si]
mov 16[si], ax
add si, 2
loop s
mov ax, 4c00h
int 21h
codesg ends
end start
7.8 [BX+SI]和[BX+DI]
即 mov ax, [bx+si] 或写作 mov ax, [bx][si]
- 问题 7.4
7.9 [bx+si+idata]和[bx+di+idata]
可以写作:
mov ax, [bx+200+si]
mov ax, [200+bx+si]
mov ax, 200[bx][si]
mov ax, [bx].200[si]
mov ax, [bx][si].200
- 问题 7.5
7.10 不同的寻址方式的灵活应用
- 问题 7.6
assume cs:codesg, ds:datasg
datasg segment
db '1. file '
db '2. edit '
datasg ends
这个问题要将数据段的英文首字母大写.
即演示寻址方式的灵活性.
- 问题 7.7
assume cs:codesg, ds:datasg,ss:stacksg
datasg segment
db 'ibm '
db 'dec '
db 'dos '
db 'vax '
datasg ends
stacksg segment
dw 0,0,0,0,0,0,0,0
stacksg ends
codesg segments
start: mov ax, stacksg
mov ss, ax
mov sp, 16
mov ax, datasg
mov ds, ax
mov bx, 0
mov cx, 4
s0: push cx
mov si, 0
mov cx, 3
s: mov al, [bx+si]
and al, 11011111b
mov [bx+si], al
inc si
loop s
add bx, 16
pop cx
loop s0
mov ax, 4c00h
int 21h
codesg ends
end start
Chapter 8, 数据处理的两个基本问题
描述性表示:
reg: ax, bx, cx, dx, ah, al, bh, bl, ch, cl, dh, dl, sp, bp, si, di
sreg: ds, ss, cs, es
8.1 bx, si, di 和 bp
- 只有 bx, si, di, bp 能用来内存单元寻址. 即用在
[]里面. - 可以组合使用
- bp 默认对应的是段地址在 ss 段寄存器.
8.2 机器指令处理的数据在什么地方
| 机器码 | 汇编指令 | 指令执行前数据的位置 |
|---|---|---|
| 8E1E0000 | mov bx, [0] | 内存, ds:0 |
| 89C3 | mov bx, ax | CPU 内部, ax 寄存器 |
| BB0100 | mov bx, 1 | CPU 内部, 指令缓冲器 |
8.3 汇编语言中数据位置的表达
-
立即数 idata
即直接包含在机器指令中的数据. -
寄存器
指令要处理的数据在寄存器中. -
段地址 SA 和 偏移地址 EA
数据在内存中, 用段地址和偏移地址来取出数据.
8.4 寻址方式
给各种寻址方式命了名.
8.5 指令要处理的数据有多长
- 使用寄存器即代表操作大小
- 没有指明寄存器则可以显式声明
mov word ptr ds:[0], 1
mov byte ptr ds:[0], 1
- 如果用特殊指令, 则会使用该指令的指定长度, 比如
PUSH针对字进行操作
8.6 寻址方式的综合应用
mov ax, seg
mov ds, ax
mov bx 60h
mov word ptr [bx+0ch], 38
add word ptr [bx+0eh], 70
mov si, 0
mov byte ptr [bx+10h+si], 'V'
inc si
mov byte ptr [bx+10h+si], 'A'
inc si
mov byte ptr [bx+10h+si], 'X'
8.7 div 指令
使用DIV指令需要注意以下问题
- 除数, 有8bit和16bit两种, 在一个寄存器或内存单元中.
- 被除数, 默认放在AX或 AX和DX中
- 16bit, 则除数为8bit, 默认存放在 AX
- 32bit, 则除数为16bit, 默认存放在 AX和DX, DX 存放高16bit, AX 存放 低16bit
- 结果
- 除数为8bit, AL存储商, AH 存储余数
- 16bit, AX存储商, DX 存储余数
8.8 伪指令 dd
db, byte
dw, word
dd, double word
- 问题 8.1
8.9 dup
db 3 dup (0) 定义3个字节, 都是0, 等价于 0, 0, 0. 通常用来初始化大量的数据.
实验 7, 寻址方式在结构化数据访问中的应用
.......
Chapter 9, 转移指令的原理
可以修改IP, 或同时修改CS和IP的指令统称为转移指令
-
按类分
- JMP ax, 段内转移, 只修改IP
- JMP 1000:0 段间转移, 同时修改CS, IP
-
按修改范围
- 短转移: -128 - 127
- 近转移: -32768 - 32767
-
直接分类
- 无条件转移, JMP 等
- 条件转移
- 循环指令
- 过程
- 中断
9.1 操作符 Offset
start: mov ax, offset start; 相当于 mov ax, 0
s: mov ax, offset s; 相当于 mov ax, 3
- 问题 9.1
assume cs:codesg
codesg segment
s: mov ax, bx
mov si, offset s
mov di, offset s0
mov ax, cs:[si]
mov cs:[di], ax
s0: nop ; 两个nop 正好一个word, 这算冯诺依曼体系的优点了, 哈佛体系就不能边运行边修改code segment.
nop
codesg ends
end s
9.2 JMP指令
9.3 依据位移进行转移的 JMP 指令
jmp short 是段内短转移, 即最多向前128byte, 向后 127byte.
start: mov ax, 0
jmp short s
add ax, 1
s: inc ax
编译到机器码后, 即为 EB{x} 其中x部分代表了向前或向后的字节数. 是编译器根据汇编指令中的标号计算出来的.
jmp near ptr 实现段内近转移, 可以达到16bit.
9.4 转移的目的地址在指令中的jmp指令
jmp far ptr 实现段间转移, cs标记段地址, IP标记偏移地址.
9.5 转移地址在寄存器中的jmp指令
即 jmp bx 等.
9.6 转移地址在内存中的jmp指令
- jmp word ptr 内存单元地址(段内转移)
- jmp dword ptr 内存单元地址(段间转移)
9.7 jcxz 指令
条件转移, 所有的条件转移指令都是短转移. 它会检测如果CX=0, 则转移.
9.8 loop 指令
所有循环指令都是短转移.
9.9 根据位移进行转移的意义
即不硬编码地址, 方便程序随时载入到任何位置, 与平台无关.
9.10 编译器对转移位移越界的检测
实验8, 分析一个奇怪的程序
实验9, 根据材料编程
Chapter 10, CALL 和 RET 指令
call 和 ret都是转移指令, 修改IP. 或者同时修改CS, IP.
10.1 ret 和 retf
ret修改io实现近转移, retf 修改 cs, ip 实现远转移.
直接执行ret, IP=0, cs:ip 指向代码段第一行.
10.2 CALL 指令
执行CALL时,
- 将当前 IP 或 CS:IP 压栈
- 转移
10.3 根据唯一进行转移的CALL指令
执行 CALL 标号, 相当于:
PUSH IP
JMP NEAR PTR 标号
即跳转到指定位置.
- ret 和 call 的例子:
; Program that demonstrates CALL and RET instructions
.386
.MODEL FLAT
ExitProcess PROTO NEAR32 stdcall, dwExitCode:DWORD
.CODE ; start of main program code
_start:
mov eax, 10 ; move data into registers
mov ebx, 20
call add2nums ; push address of next instruction
; onto the stack, and pass control
; to the address of add2nums
INVOKE ExitProcess, 0 ; exit with return code 0
PUBLIC _start ; make entry point public
add2nums:
add eax, ebx ; Add two numbers
ret ; Return result in EAX
END ; end of source code
10.4 转移的目的地址在指令中的call指令
嘛当然也要有far的call指令: call far ptr 标号
10.5 转移地址在寄存器中的CALL指令
call 16bit reg
10.6 转移地址在内存中的CALL指令
call word ptr 内存单元地址
例如:
mov sp, 10h
mov ax, 0123h
mov ds:[0], ax
mov word ptr ds:[2], 0
call dword ptr ds:[0]
10.7 CALL 和 RET 的配合使用
- 问题 10.1
10.8 mul 指令
8 位结果放在 AX, 16 位 结果放在 DX, AX.
mov al, 100
mov bl, 10
mul bl
ax=1000(03E8H)
mov ax, 100
mov bx, 10000
mul bx
ax=4240h, dx=000fh
10.9 模块化程序设计
10.10 参数和结果传递的问题
assume cs:code
data segment
dw 1,2,3,4,5,6,7,8
dd 0,0,0,0,0,0,0,0
data ends
code segment
start: mov ax, data
mov ds, ax
mov si, 0
mov di 16
mov cx, 8
s: mov bx, [si]
call cube
mov [di], ax
mov [di].2, dx
add si, 2
add di, 4
loop s
mov ax, 4c00h
int 21h
cube: mov ax, bx
mul bx
mul bx
ret
code ends
end start
10.11 批量数据的传递
assume cs:code
data segment
db 'conversation'
data ends
code segment
start: mov ax, data
mov ds, ax
mov si, 0
mov cx, 12
call capital
mov ax, 4c00h
int 21h
capital: and byte ptr [si], 11011111b
inc si
loop capital
ret
code ends
end start
10.12 寄存器冲突的问题
assume cs:code
data segment
db 'word', 0
db 'unix', 0
db 'wind', 0
db 'good', 0
data ends
code segment
start: mov ax, data
mov ds, ax
mov bx, 0
mov cx, 4
s: mov si, bx
call captial
add bx, 5
loop s
mov ax. 4c00h
int 21h
capital: push cx
push si
change: mov cl, [si]
mov ch, 0
jcxz ok
and byte ptr [si], 11011111b
inc si
jmp short change
ok: pop si
pop cx
ret
code ends
end start
实验 10 编写子程序
11.6 adc 指令
add128: push ax
push cs
push si
push di
sub ax, ax
mov cx, 8
s: mov ax, [si]
adc ax, [di]
mov [si], ax
inc si
inc si
inc di
inc di
loop s
pop di
pop si
pop cx
pop ax
ret
11.7 sbb 指令
sbb 带借位减法指令. 同样利用CF位上的借位值.
11.8 cmp 指令
cmp是比较指令, cmp 的功能相当于减法指令, 只是不保存结果.
cmp ax, bx
如果ax==bx, 则 ax-bx=0, zf = 1
ax != bx, zf = 0,
ax < bx, cf = 1,
ax >= bx cf = 0
ax > bx cf = 0, zf = 0
ax <= bx, cf = 1, 或 zf = 1
11.9 检测比较结果的条件转移指令
| 指令 | 含义 | 检测的相关标志位 |
|---|---|---|
| je | 等于则转移 | zf = 1 |
| jne | 不等于则转移 | zf = 0 |
| jb | 小于则转移 | cf = 1 |
| jnb | 不小于则转移 | cf = 0 |
| ja | 大于则转移 | cf = 0, zf = 0 |
| jna | 不大于则转移 | cf=1或 zf = 1 |
编程实现如果 ah=bh, 则 ah=ah+ah, 否则 ah=ah+bh
cmp ah, bh
je s
add ah, bh
jmp short ok
s: add ah, ah
ok: ....
所以鉴于比较命令检测的都是FLAG寄存器, 因此一定要注意其中的值. 不要使用旧值.
- 编程, 统计data短中树脂位8的字节的个数, 用ax保存统计结果
data segment
db 8, 11, 8, 1, 8, 5, 63, 38
data ends
code segment
mov ax, data
mov ds, ax
mov bx, 0
mov ax, 0
mov cx, 0
s: cmp byte ptr [bx], 8
je ok
jmp short next
ok: inc ax
next: inc bx
loop s
code ends
- 编程, 统计data段中数值大于8的字节的个数, 用ax保存统计结果.
mov ax, data
mov ds, ax
mov ax, 0
mov bx, 0
mov cx, 8
s: cmp byte ptr [bx], 8
jna next
inc ax
next: inc bx
loop s
11.10 DF 标志和串传送指令
DF位是方向标志位, 在串处理中, 控制si, di的增减.
df=0, si, di 递增, 反之递减.
串传送 movsb 将 ds:si 指向的内存单元中的字节送入 es:di, 然后根据df, 将si,di递增或递减.
movsw, 移动word, 并si,di +-2. 这两个串传送指令通常搭配rep使用.
因此df决定向哪个地址方向复制数据.
cld 指令可以将 df设置为0, std 则置为1.
- 编程, 用串传送指令, 将data段中的第一个字符串复制到它后面的空间中
data segment
db 'Welcome to masm!'
db 16 dup (0)
data ends
code segment
mov ax, data
mov ds, ax
mov si, 0
mov es, ax
mov di, 16
mov cx, 16
cld
rep movsb
code ends
即DS:SI事项原始数据起始位置, ES:DI 指向目标地址起始位置, 然后设置cx为需要复制的大小, cld 设置df指向, rep movsb 开始复制.
11.11 pushf 和 popf
pushf 将标志寄存器值压栈, popf 则从栈弹出数据到标志寄存器
mov ax, 0
push ax
popf
mov ax, 0FFF0H ; 0000 1111 1111 1111 0000
add ax, 0010H ; 0001 0000 0000 0000 0000
pushf
pop ax
and al, 11000101B
and ah, 00001000B
执行完毕后AX = , 即求出FLAG寄存器变动的bit. 然后按bit 与计算.
11.12 标志寄存器在 Debug 中的表示
Chapter 12, 内中断
即 CPU内部产生的中断
12.1 内中断的产生
如何产生内中断
- 除法错误 : 0
- 单步执行 : 1
- 执行 into : 4
- 执行 int : 需要指定中断类型码
12.2 中断处理程序
编写的用来中断处理的程序角中断处理程序. 因此需要映射中断与程序.
12.3 中断向量表
在内存中存放 256 个中断源死哦对应的中断处理程序的入口地址.
在8086中, 中断向量表默认存放在 0000:0000 - 0000:03FF 中, 高地址存放段地址, 低地址存放偏移地址.
12.4 中断过程
中断过程是CPU自动完成的.
中断过程还要记录下之前执行的位置, 以便中断结束后继续运行.
具体流程为:
- 获取中断类型码
- FLAG寄存器入栈
- 设置 FLAG 寄存器 TF, IF 为0
- CS入栈
- IP 入栈
- 从内存地址为终端类型吗 * 4, *4+2 取出IP:CS
简化即:
- 获取终端类型码N
- pushf
- TF=0, IF=0
- PUSH CS
- PUSH IP
- IP=N4, CS=N4+2
12.5 中断处理程序和 iret 指令
编写中断处理程序通常是:
- 保存用到的寄存器
- 处理中断
- 恢复用到的寄存器
- 用iret指令返回
iret相当于:
pop IP
pop CS
popf
12.6 除法错误中断的处理
默认直接显示信息并退出
12.7 编程处理0号中断
讨论了如何改写中断处理程序, 以及需要放到安全的内存地址
12.8 安装
利用movsb将中断处理程序放到需要的位置.
assume cs:code
code segment
start: mov ax, cx
mov ds, ax
mov si, offset do0
mov ax, 0
mov es, ax
mov di, 200h
mov cx, offset do0end-offset do0; "-" 是编译期运算指令, 可以做减法.
cld ; 传输方向为正
rep movsb
; 设置中断向量表
mov ax, 4c00h
int 21h
do0: 显示字符串 'Overflow!'
mov ax, 4c00h
int 21h
do0end: nop
code ends
end start
12.9 do0
assume cs:code
code segment
start: mov ax, cs
mov ds, ax
mov si, offset do0 ; 设置 ds:si 指向源地址
mov ax, 0
mov es, ax
mov di, 200h ; 设置 es:di 指向目的地址
mov cs, offset do0end-offset do0 ; 设置cs为传输长度
cld ; 设置方向为正
rep movsb
; 设置中断向量表
mov ax, 0
mov es, ax
mov word ptr es:[0*4], 200h ; 中断向量地址为0000:0200h 固定地址.
mov word ptr es:[0*4+2], 0
mov ax, 4c00h
int 21h
do0: jmp short do0start
db "Overflow!" ; 这里强调了如果数据放到数据段, 运行完毕数据段内存就释放了. 所以硬编码到程序中.
do0start: mov ax, cs
mov ds, ax
mov si, 202h ; 设置 ds:si 指向字符串
mov ax, 0b800h
mov es, ax
mov di, 12*160+36*2 ; 设置 es:di 指向显存空间的中间位置
mov cx, 9 ; 设置 cx为字符串长度.
s: mov al, [si]
mov es:[di], al
inc si
add di, 2
loop s
mov ax, 4c00h
int 21h
do0end: nop
code ends
end start
12.10 设置中断向量
见上文代码
12.11 单步中断
CPU提供单步中断为实现单步执行提供了机制.
12.12 响应中断的特殊情况
不响应中断:
- 设置ss的情况, CPU默认不响应中断直接执行吓一条, 为了防止栈地址设置错误. 因此下一条应该是sp设置.
mov ax, 1000h
mov ss, ax
mov sp, 0
Chapter 13, int指令
13.1 int指令
int为手动触发中断.
assume cs:code
code segment
start: mov ax, 0b800h
mov es, ax
mov byte ptr es:[12*160+40*2], '!'
int 0
code ends
end start
13.2 编写供应用程序调用的中断例程
assume cs:code
code segment
start: mov ax, cs
mov ds, ax
mov si, offset sqr
mov ax, 0
mov es, ax
mov di, 200h
mov cx, offset sqrend-offset sqr
cld
rep movsb
mov ax, 0
mov es, ax
mov word ptr es:[7ch*4], 200h
mov word ptr es:[7ch*4+2], 0
mov ax, 4c00h
int 21h
sqr: mul ax
iret
sqrend: nop
code ends
end start
安装程序:
assume cs:code
code segment
start: mov ax, cs
mov ds, ax
mov si, offset capital
mov ax, 0
mov es, ax
mov di, 200h
mov cx, offset capitalend-offset capital
cld
rep movsb
mov ax, 0
mov es, ax
mov word ptr es:[7ch*4], 200h
mov word ptr es:[7ch*4+2], 0
mov ax, 4c00h
int 21h
capital: push cx
push si
change: mov cl, [si]
mov ch, 0
jcxz ok
and byte ptr [si], 11011111b
inc si
jmp short change
ok: pop si
pop cx
iret
capitalend: nop
code ends
end start
13.3 对 int, iret 和栈的深入理解
13.4 BIOS 和 DOS 所提供的中断例程
BIOS主要包含以下几部分内容:
- 硬件系统的检测和初始化程序
- 外部中断和内部中断的中断例程
- 用于对硬件设备进行IO操作的中断例程
- 其他和硬件系统相关的中断例程
和硬件设备相关的DOS中断例程中, 一般都调用了BIOS的中断例程
13.5 BIOS 和 DOS 中断例程的安装过程
即先加载BIOS的中断向量, BIOS中的中断程序由于是ROM的, 已经在内存了. 然后执行 int19h, 引导操作系统. 系统启动后, 也将需要的历程装入内存并建立中断向量.
13.6 BIOS 中断例程应用
解释了如何显示字符
13.7 DOS 中断例程应用
mov ah, 4ch
mov al, 0
int 21h
即调用 21h 中断例程的 4ch 号子程序, 功能为程序返回.
即
mov ax, 4c00h
int 21h
Chapter 14, 端口
CPU 可以直接读写以下3个地方的数据
- CPU内部的寄存器
- 内存单元
- 端口
14.1 端口的读写
端口读写用 in, out
访问端口:
in al, 60h ; 从60h端口读入一个字节.
mov ax, 3f8h
in al, dx
out dx, al
14.2 CMOS RAM 芯片
14.3 shl 和 shr 指令
shl, 逻辑左移指令
将一个寄存器或内存单元的数据向左位移, 将在以后移出的一位写入CF中, 最低位用0补充.
mov al, 01001000b
shl al, 1 ; al左移一位.
14.4 CMOS RAM中存储的时间信息
CMOS中时间使用BCD码存放的.
Chapter 15, 外中断
15.1 接口芯片和端口
CPU 通过端口 和外部设备通信
15.2 外中断信息
外中断源分为两类:
- 可屏蔽中断, 即可以不响应. IF = 1. 相应中断, IF=0 则不响应.
sti 设置 if=1, cli, if = 0
- 不可屏蔽中断, 中断类型码固定为2.
几乎所有外设引发的外部中断, 都是可屏蔽中断.
15.3 PC机键盘的处理过程
- 键盘输入
扫描码长度为一个字节, 通码的第7位为0, 断码的第7位为1.
断码=通码+80h
- 引发9号中断
键盘输入到达60h端口, 芯片会向CPU发出中断类型为9的可屏蔽中断信息. CPU 检测IF=1, 响应中断, 引发中断例程, 执行 int9中断例程.
-
执行int9 中断例程
-
读取60h端口中的扫描码.
-
字符键将对应的字符码送入内存的BIOS键盘缓冲区, 控制键和切换键则转变为状态字节, 存入内存中存储状态字节的单元
-
对键盘系进行相关控制, 比如向相关芯片发出应答信息.
BIOS 的键盘缓冲区是系统启动后, BIOS存放键盘输入的内存区域. 可以存储15个键盘输入.